

In today's fast-paced world, people often seek ways to increase their productivity and efficiency. One might desire the superpower of being able to transcribe and summarize meeting audio, however, this can be a tedious and time-consuming task, especially when dealing with numerous recordings. Fortunately with today’s AI environment, we can easily leverage tools to perform highly-accurate audio file transcription and then provide that transcription to an large-language model to perform summarization.
In this post, we’ll write an example python script that performs transcription and summarization using OpenAI’s Whisper and GPT APIs. This script is designed to provide an automated solution that can continuously monitor a specified directory for new audio files and automatically transcribe and summarize them once they are detected.
To get started, first import a number of python libraries by running the following command:
pip install openai dotenv
This will install the OpenAI and dotenv packages.
Next, we’ll create a new file, main.py, and begin importing the packages we’ll be using in this script, along with loading environment variables.
import os
from os import listdir, getenv
from os.path import isfile, join, expanduser
import time
import json
import tiktoken
from dotenv import load_dotenv
import openai
load_dotenv()
opanai_api_key = getenv("OPENAI_API_KEY")
if (opanai_api_key == None):
print("OPENAI_API_KEY is not set")
exit(1)
monitoring_dir = getenv("SUMMARIZER_PATH")
if (monitoring_dir == None):
monitoring_dir = expanduser('~/Music/Teams')
openai.api_key = opanai_api_key
Next, we’ll write some utility functions that will monitor files in a folder. These functions form the bulk of the script, but perform the least amount of ‘magic’. The fileWatcher function polls the specified directory and identifies new audio or transcript files. Now this is where the magic starts to come in - For each new .mp3 file, it calls convertAudioToText to transcribe the audio, likewise, for each new JSON transcript file, it calls summarizeText to generate a summary.
We structure the processor this way to capture the results from our calls to the Whisper API so we don’t necessarily need to reprocess audio files over again.
def fileInDirectory(my_dir: str):
onlyfiles = [f for f in listdir(my_dir) if isfile(join(my_dir, f))]
return(onlyfiles)
def listComparison(OriginalList: list, NewList: list):
differencesList = [x for x in NewList if x not in OriginalList]
return(differencesList)
def fileWatcher(my_dir: str, pollTime: int):
while True:
if 'watching' not in locals(): #Check if this is the first time the function has run
previousFileList = fileInDirectory(my_dir)
watching = 1
print('First Time')
print(previousFileList)
time.sleep(pollTime)
newFileList = fileInDirectory(my_dir)
fileDiff = listComparison(previousFileList, newFileList)
previousFileList = newFileList
if len(fileDiff) == 0: continue
for file in fileDiff:
if file.lower().endswith(".mp3"):
print(f"mp3 file found {file}")
convertAudioToText(my_dir, join(my_dir, file))
elif file.lower().endswith("-transcript.json"):
print(f"json transcript file found: {file}")
summarizeText(my_dir, join(my_dir, file))
Now, we’ll write the functions that convertAudioToText function uses the Whisper model to transcribe audio files. It loads the audio file and then calls the openai.Audio.transcribe method. The transcription is saved to a JSON file in the same directory as the audio file.
def convertAudioToText(my_dir: str, audioFilePath: str):
print("converting audio to text for file: " + audioFilePath + "...")
audio_file = open(audioFilePath, "rb")
params = dict(prompt="Speaker 1: Hello, World.\\nSpeaker 2: That's Great.\\n")
transcript = openai.Audio.transcribe("whisper-1", audio_file, **params)
with open(join(my_dir, os.path.abspath(os.path.splitext(audioFilePath)[0]) + "-transcript.json"), "w") as outfile:
outfile.write(json.dumps(transcript, indent=4))
print("text: " + transcript["text"])
return transcript
The summarizeText function is responsible for summarizing the transcriptions. It first reads the transcript from the JSON file we received from Whisper. Since GPT has a limit on the maximum number of tokens it can process at one time, we split the transcript in creating chunks of the text to be summarized. It then uses the GPT-3.5-turbo model from OpenAI to generate summaries. For each chunk, a summary is generated and saved to a JSON file. Finally, all the summaries are combined and saved to a text file.
def create_chunks(text, chunkSize, overlap):
tt_encoding = tiktoken.get_encoding("gpt2")
tokens = tt_encoding.encode(text)
total_tokens = len(tokens)
chunks = []
for i in range(0, total_tokens, chunkSize - overlap):
chunk = tokens[i:i + chunkSize]
chunks.append(chunk)
return chunks
def summarizeText(my_dir: str, whisperFilePath: str):
print("summarizing text...")
jsonData = open(whisperFilePath)
data = json.load(jsonData)
text = data["text"];
chunks = create_chunks(text, 3000, 50)
tt_encoding = tiktoken.get_encoding("gpt2")
final_response = [];
for index, chunk in enumerate(chunks):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant that summaries transcripts for users. You make an attempt to identify the most important parts of the transcript ."},
{"role": "user", "content": f"Please provide a detailed summary of the following transcript pointing out five key highlights and any action items. Additionally, list each individual in the conversation, provide their names if available along with their roles. Additionally, list any questions made in the conversation and provide what answers that were provided. Finally, include any key statements they made and indicate the person who said them:\\n {tt_encoding.decode(chunk)}"},
]
)
with open(join(my_dir, os.path.abspath(os.path.splitext(whisperFilePath)[0]) + f"-summary-{index}.json"), "w") as outfile:
outfile.write(json.dumps(response, indent=4))
final_response.append(response["choices"][0]["message"]["content"])
with open(join(my_dir, os.path.abspath(os.path.splitext(whisperFilePath)[0]) + f"-summary.txt"), "w") as outfile:
outfile.write(' '.join(map(str, final_response)))
print(final_response)
return response
[data:image/svg+xml,%3csvg%20xmlns=%27http://www.w3.org/2000/svg%27%20version=%271.1%27%20width=%2738%27%20height=%2738%27/%3e](data:image/svg+xml,%3csvg%20xmlns=%27http://www.w3.org/2000/svg%27%20version=%271.1%27%20width=%2738%27%20height=%2738%27/%3e)
Note the line where we’re giving GPT instructions on what to perform. As written, it instructs GPT to create a summary of the transcript, along with attempting to determine the members of the meeting and lists out any questions and quotes from the meeting. We can change this prompt if necessary so that it provides different results.
Finally, we’ll just invoke the filewatcher so that it monitors the folder that we indicated.
fileWatcher(monitoring_dir, 1)
To use this script, at the minimum, you’ll need to set the OPENAI_API_KEY environment variable to the value of your OpenAI API Key.
export OPEN_API_KEY=xxxxx
Next, we can just invoke this script using python
python main.py
And start dropping files into the indicated folder. Personally using a tool called Audio Hijack that is able to capture system audio and, when the recording is stopped, copy that audio into the summarizer input folder.
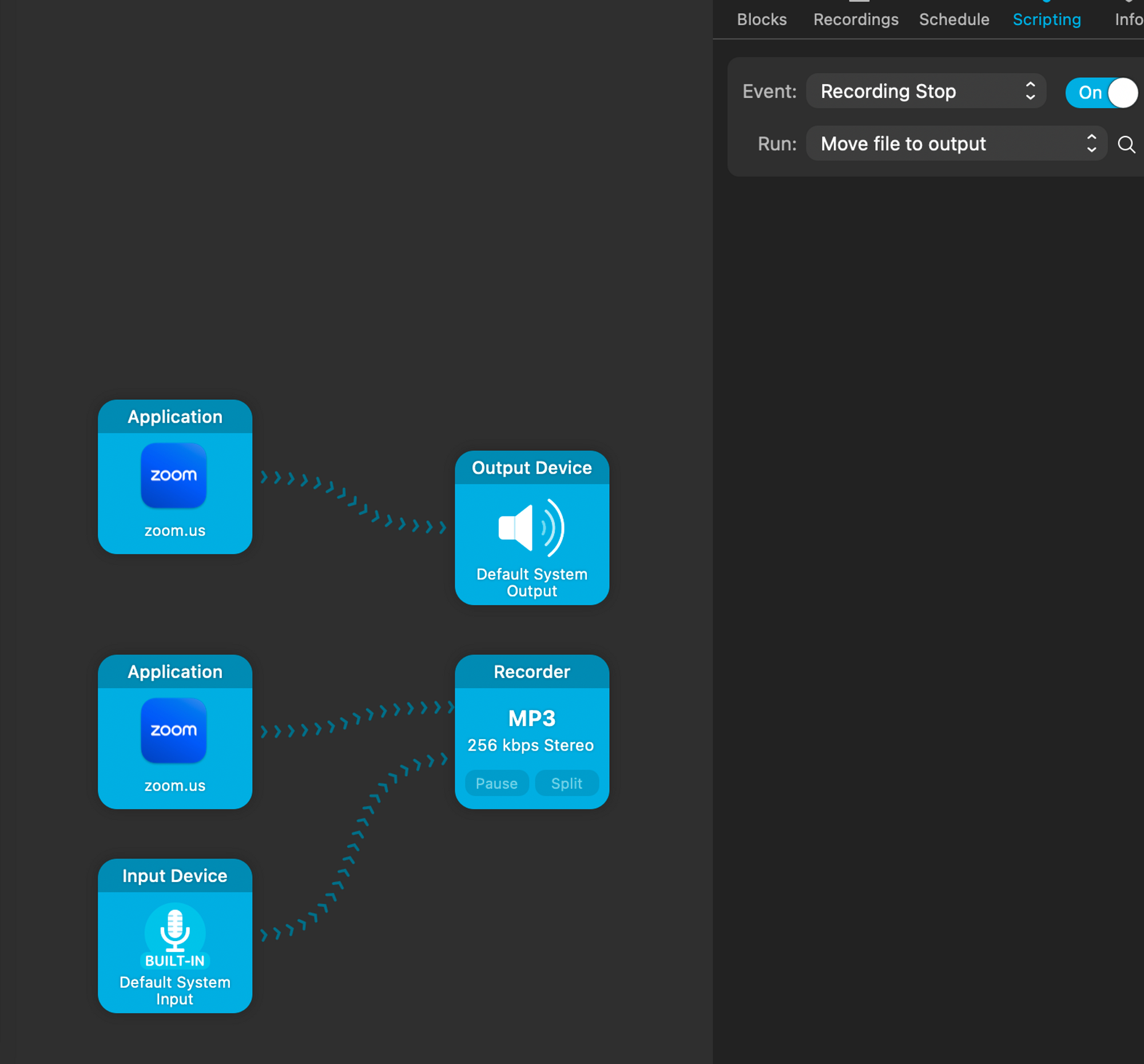
This lets me completely automate the process of transcribing meetings. On other operating systems, some similar tools include VoiceMeeter, Total Recorder (Windows) or JackAudio, PulseMeeter (Linux) to be able to record system audio.